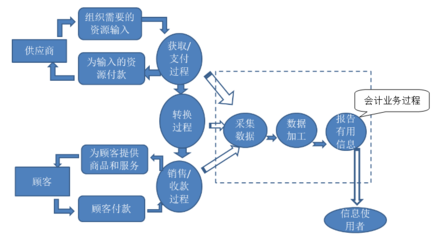
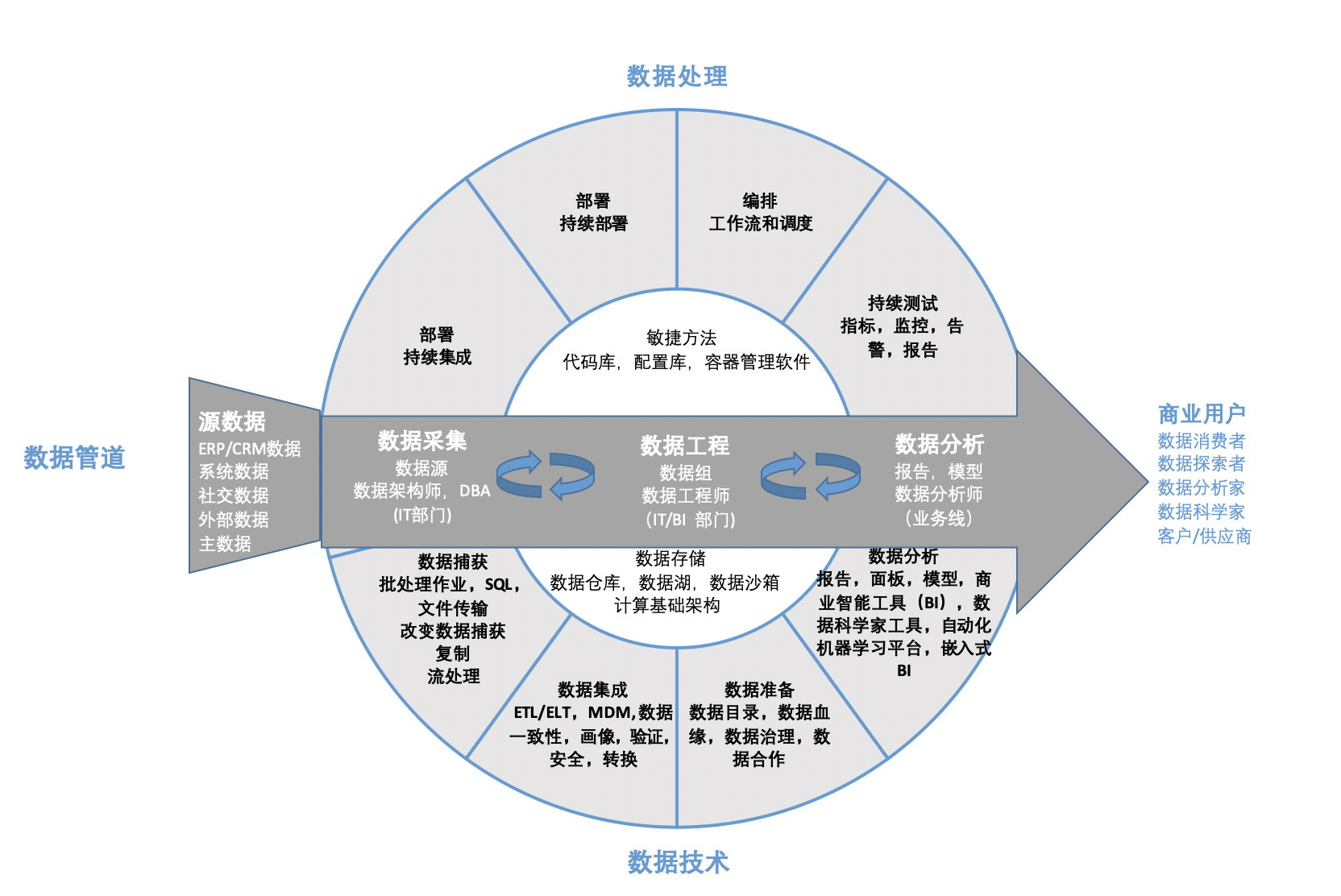
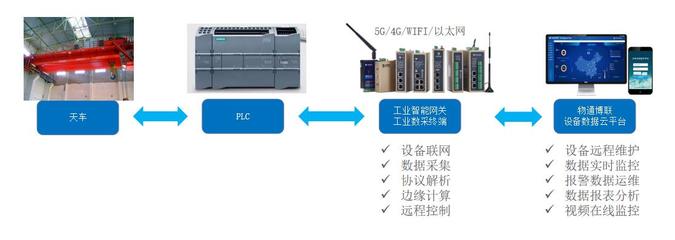
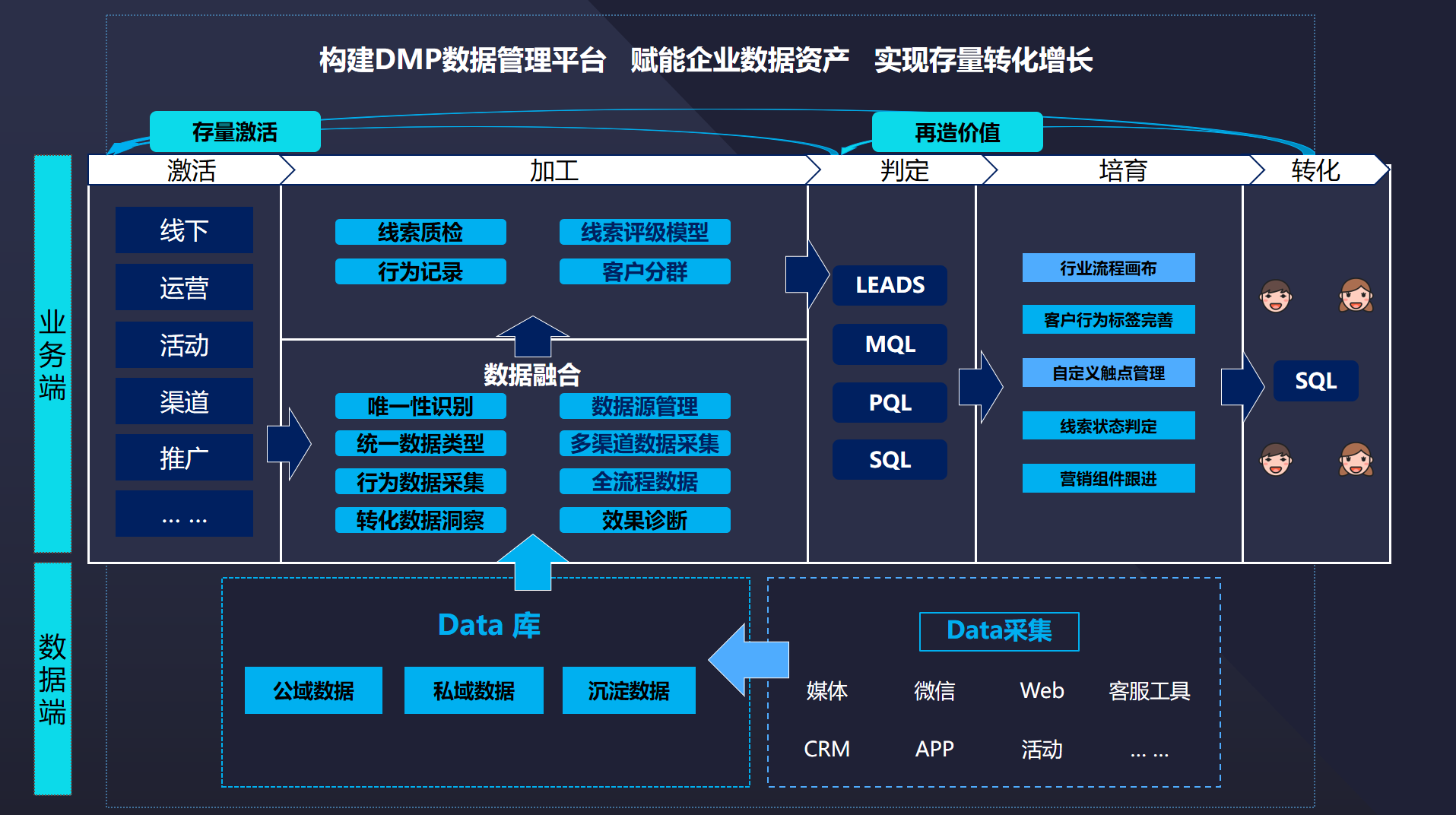
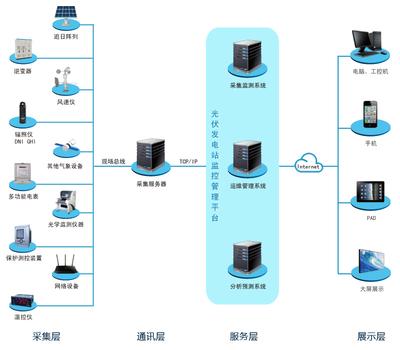
从图片到数据 浅谈“poYBAGQzvJmARd7-AADVrJprVa4442.jpg”背后的数据采集技术
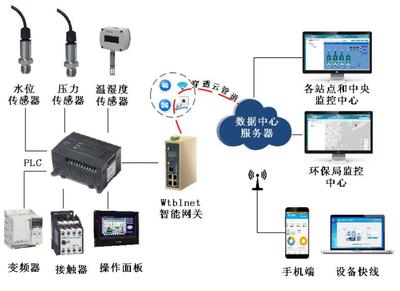
在现代信息社会中,一张看似简单的图片,如“poYBAGQzvJmARd7-AADVrJprVa4442.jpg”,其背后可能关联着一整套复杂的数据采集、处理与应用流程。这个过程不仅是技术性的,也涉及到数据价值挖掘与隐私安全的平衡。
一、图片本身:数据的初始载体
这张以复杂字符串命名的图片文件,其文件名本身就蕴含了初步的数据信息。这种命名方式通常是系统自动生成的,可能基于时间戳、哈希值或特定编码规则,旨在保证文件的唯一性和可追溯性。图片的格式(.jpg)则指明了它是一种经过压缩的静态图像数据,适合存储和传输。图片文件本身作为一个数据包,包含了像素矩阵、颜色信息、EXIF数据(如拍摄设备、时间、GPS位置等)等原始数据层。
二、数据采集的触发与场景
“数据采集”围绕这张图片可能发生在多种场景下:
- 网络爬虫与内容聚合:当这张图片被发布在网站、社交媒体或电商平台时,网络爬虫程序可以自动识别并抓取图片文件及其周围的文本描述、标签、用户评论等信息,用于构建图像数据库、进行内容分析或训练AI模型。
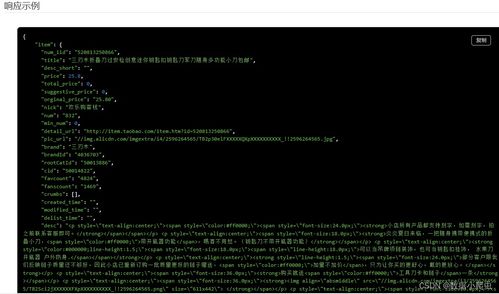
- 计算机视觉分析:通过图像识别技术,可以对图片内容进行自动化数据采集。例如,识别图中物体(如商品、人脸、场景)、提取图中文字(OCR技术)、分析图像风格、色彩分布等,将这些视觉信息转化为结构化的标签数据。
- 用户行为数据关联:在互联网平台上,用户对这张图片的点击、浏览时长、下载、分享等交互行为会被后台系统采集,并与用户ID、时间、IP地址等元数据关联,形成用户行为数据集,用于分析兴趣偏好或优化推荐算法。
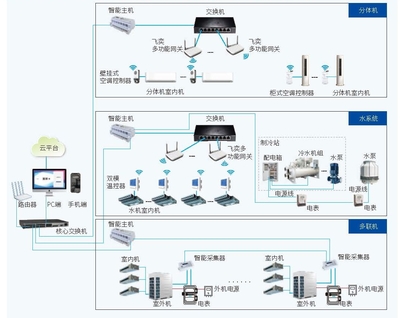
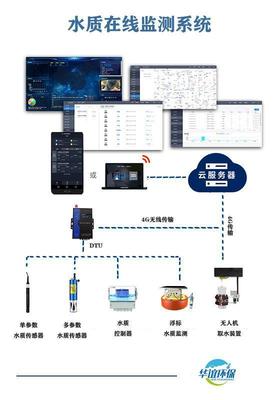
- 物联网与传感器融合:如果图片来自监控摄像头、智能手机或专业设备,其采集过程可能直接与地理位置、环境传感器数据同步,形成更丰富的时空信息记录。
三、采集后的数据处理与价值挖掘
原始数据被采集后,需要经过清洗、标注、存储和分析才能产生价值:
- 清洗与标注:去除低质量或重复图片,并由人工或AI对图片内容进行标注(例如,为图中物体打上“汽车”、“户外”、“风景”等标签),形成高质量的标注数据集,这是训练机器学习模型的关键燃料。
- 存储与管理:图片及提取的数据通常存入数据库或分布式文件系统(如HDFS),通过高效的索引便于后续检索。文件名“poYBAGQzvJmARd7-AADVrJprVa4442.jpg”可能作为主键之一。
- 分析与应用:整合后的数据可用于多种分析:
- 商业智能:电商平台分析商品图片的点击率以优化展示。
- 安全监控:通过人脸或行为识别进行安防预警。
- 学术研究:作为训练数据提升计算机视觉模型的准确性。
- 内容推荐:根据图像内容相似性为用户推荐信息。
四、伴随的挑战与考量
在数据采集过程中,必须正视以下挑战:
- 隐私与伦理:如果图片包含人脸、车牌等个人敏感信息,未经授权的采集和分析可能侵犯隐私。需要遵循相关法规(如GDPR),进行匿名化处理或获取明确同意。
- 数据质量与偏见:采集的数据集可能存在质量不均或样本偏差(如某些类别图片过多),导致后续AI模型出现偏见。
- 技术成本:大规模图片数据的采集、存储和处理需要巨大的计算资源和带宽成本。
- 版权与所有权:图片的版权归属需清晰,商业用途的数据采集必须尊重知识产权。
###
回到“poYBAGQzvJmARd7-AADVrJprVa4442.jpg”,这个看似随机的字符串,既是数据海洋中一个微小数字实体的标识,也是通往一个庞大技术生态的入口。数据采集技术正不断将这类非结构化的图片信息,转化为驱动智能时代前进的结构化知识与洞察。在享受技术红利的我们也必须审慎地构建与之匹配的数据治理框架,确保技术进步在安全、合规、公平的轨道上行进。
如若转载,请注明出处:http://www.chuanqingkeji.com/product/45.html
更新时间:2026-01-12 03:28:40